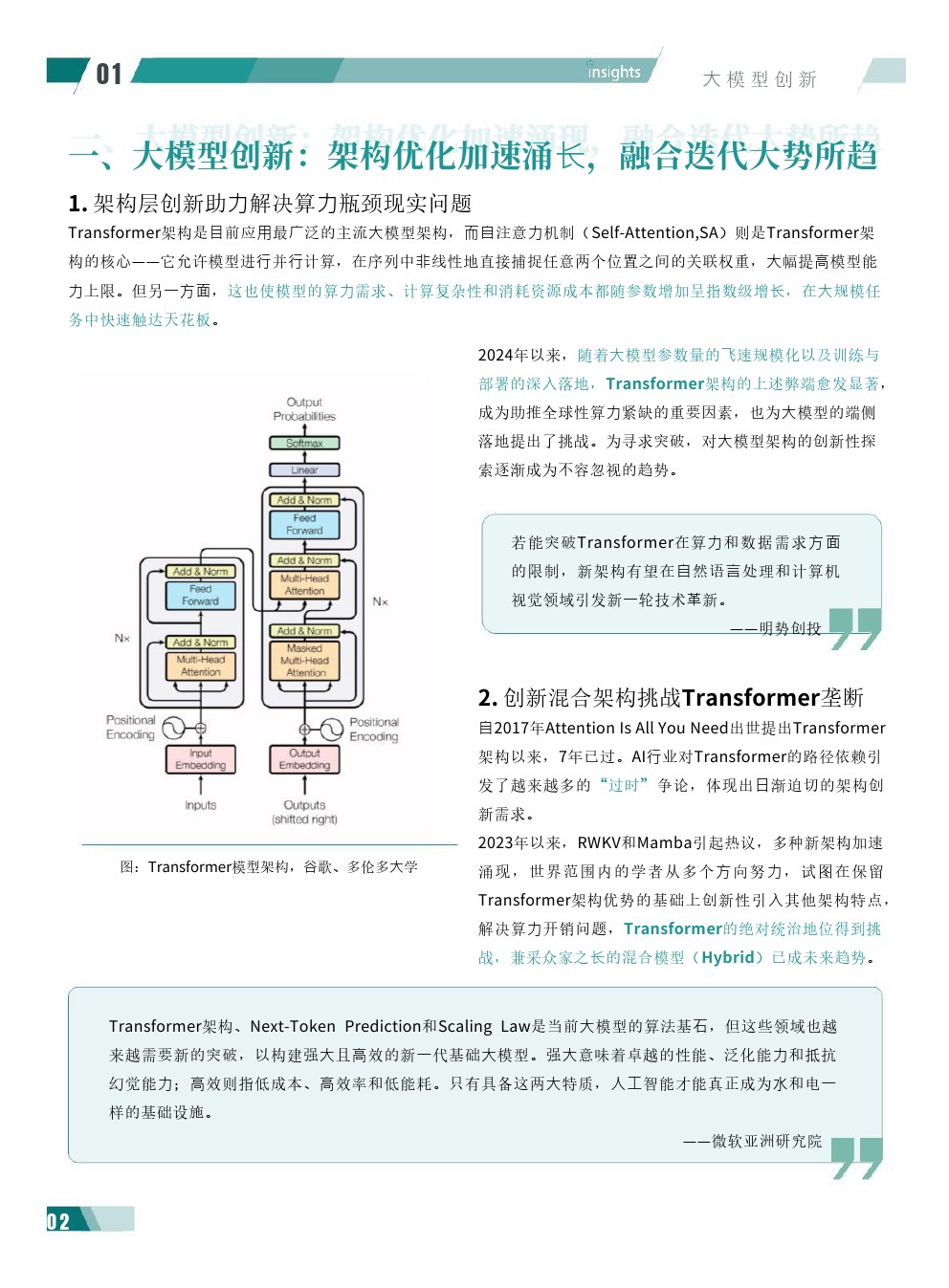


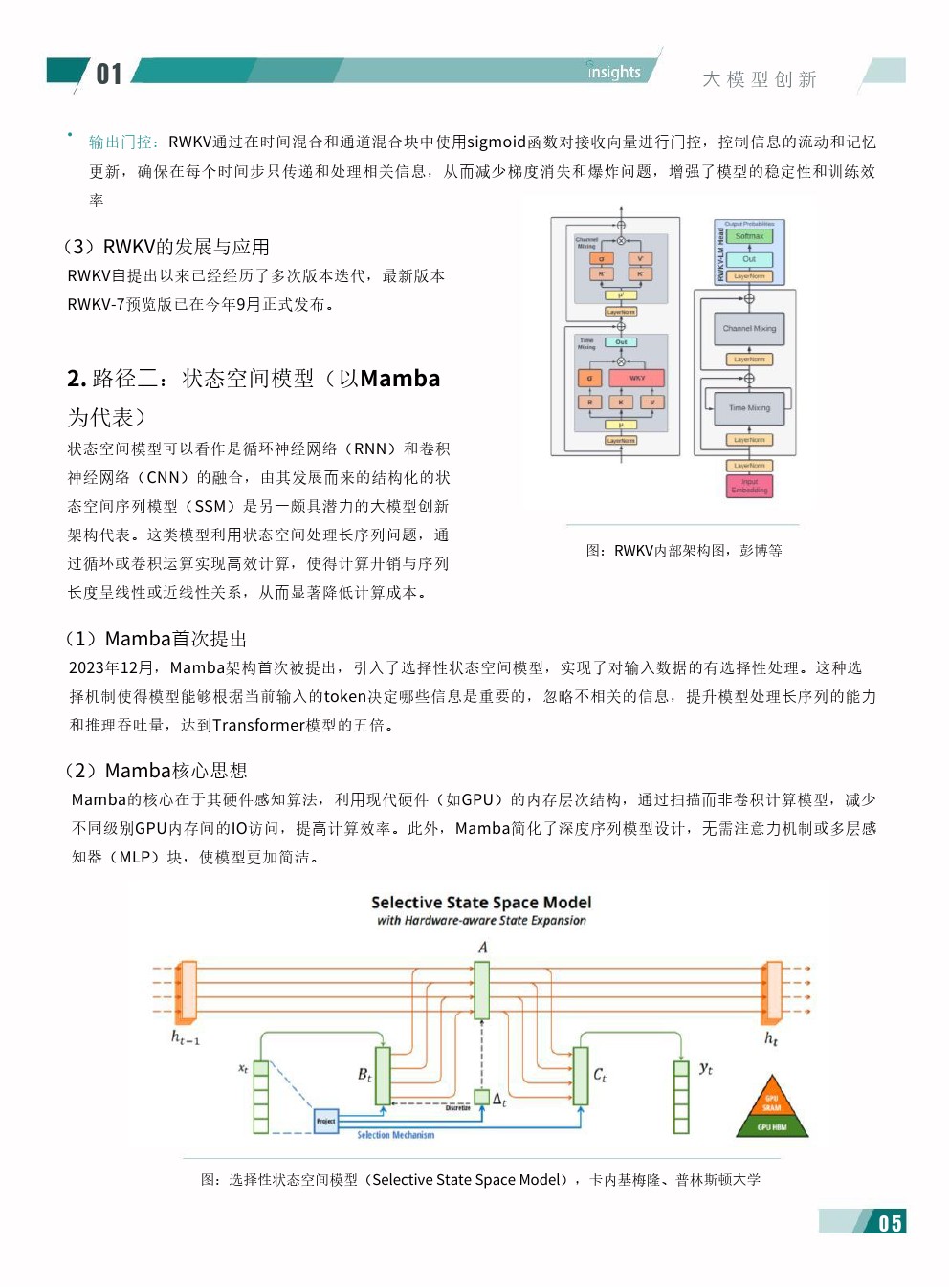
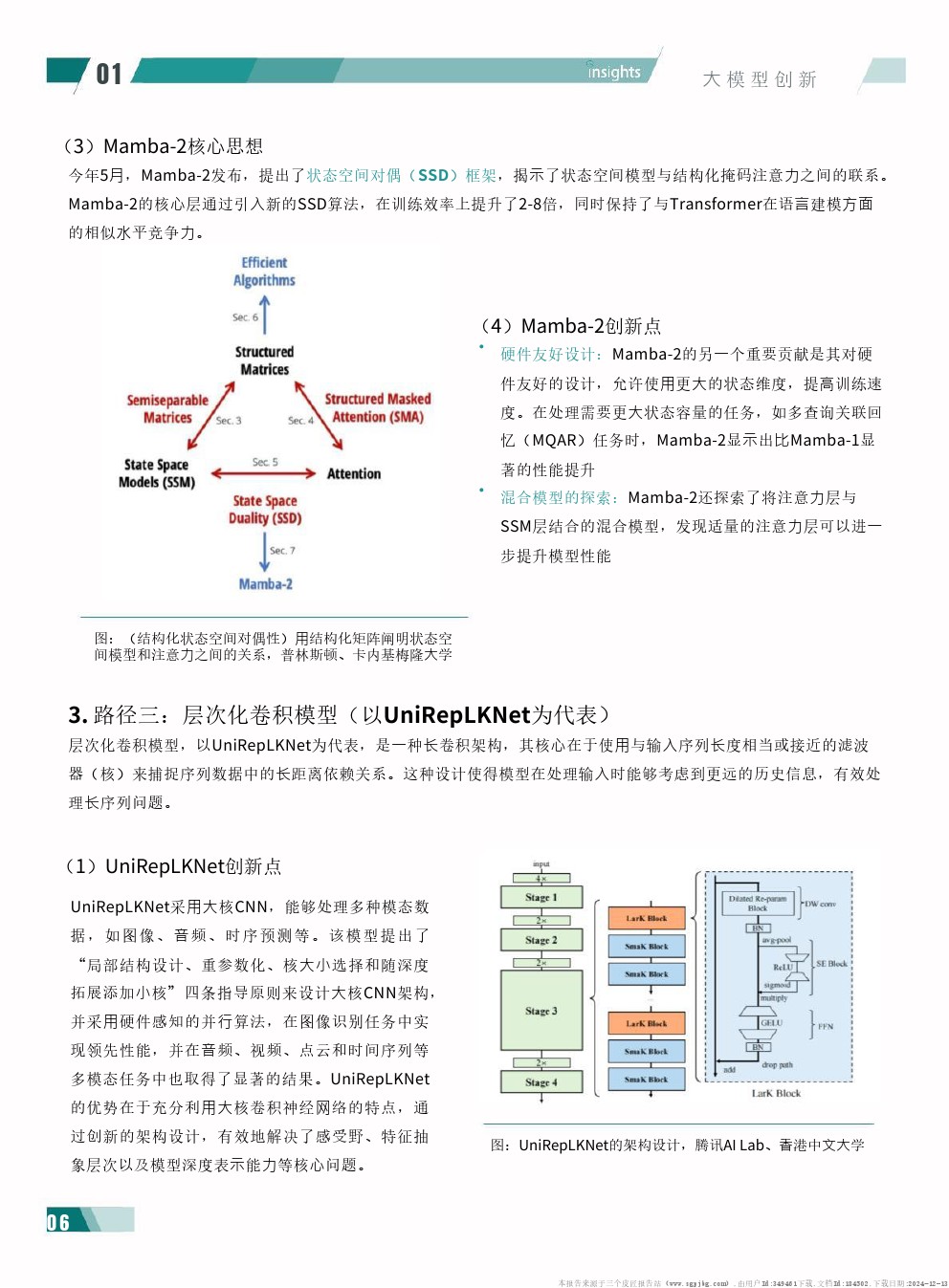


| 大模型创新:架构优化加速涌长,融合迭代大势所趋架构层创新助力解决算力瓶颈现实问题Transformer架构是目前应用最广泛的主流大模型架构,而自注意力机制(Self-Attention,SA)则是Transformer架构的核心--它允许模型进行并行计算,在序列中非线性地直接捕捉任意两个位置之间的关联权重,大幅提高模型能力上限。 但另一方面,这也使模型的算力需求、计算复杂性和消耗资源成本都随参数增加呈指数级增长,在大规模任务中快速触达天花板。 2024年以来,随着大模型参数量的飞速规模化以及训练与部署的深入落地,Transformer架构的上述弊端愈发显著成为助推全球性算力紧缺的重要因素,也为大模型的端侧落地提出了挑战。 为寻求突破,对大模型架构的创新性探索逐渐成为不容忽视的趋势。
|










报告派(baogaopai.com)致力于发现互联网资讯,以信息普及传播价值为目的,每日分享热点行业报告、数据图表、精选研读深度报告,致力成为专业的行业研究报告与数据分享平台!
 百度小程序
百度小程序 访问手机版
访问手机版 微信公众号
微信公众号 微信小程序
微信小程序